
Our beliefs
1. Although LLMs provide language fluency and are the main AI tools used by the broader public, they lack persistent reasoning and auditable memory in addition to being structurally limited:
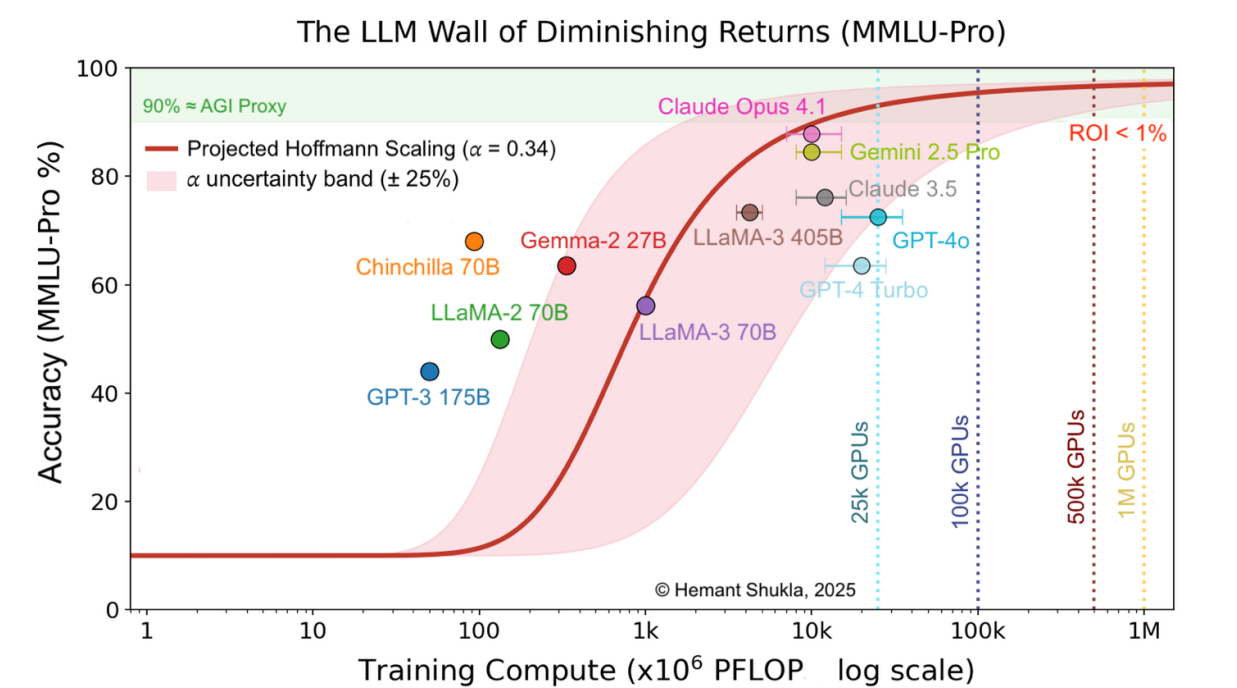
Graph from The AI Scaling Wall of Diminishing Returns Of LLMs, Electric Dogs, and General Relativity by Hemant Shukla
Scaling of MMLU-Pro accuracy vs. total training compute PFLOP. MMLU-Pro accuracy (%) of major foundational (< 1010 PFLOP) and frontier (≥ 1010 PFLOP) models plotted against total training compute. The fitted red curve and shaded uncertainty band (𝛼 = 0.34 ± 0.08) illustrate the predicted scaling behavior: rapid early gains that flatten beyond the YottaFLOP scale, approaching an asymptotic limit near 95 % accuracy.
2. World models may solve some of the issues LLMs encounter, but they are years away and can be challenged in various areas.
3. All the models above lack auditability and fail to provide verifiable accuracy, or cannot be used simultaneously as they are.
4. Current AI systems, including LLMs and RAG pipelines, operate like filing cabinets — they retrieve information but cannot distill new experience into genuine understanding. From the moment they're deployed, they go stale. Every organization using them is working with yesterday's intelligence.
We build AI inspired by how humans learn, remember, and reason - systems that get better with use, retain knowledge, and make decisions you can verify and control.